Introduction
Apache Kafka is a distributed and decentralized publish and describe system. To reduce contention, Kafka uses the concept of partitions to allow minimal coordination between the production and consumption of messages. However, due to the nature of partition growth, an unbalanced state may be created during normal use. This can lead to performance loss and underutilization. In addition, since future use is difficult to predict, newly created sets of partitions may not be optimally placed. This paper will attempt to formalize the concept of partitions and balance within a Kafka cluster, then introduce a constraint based formula to achieve balance in practice.
Problem Statement
Typical usage of Kafka consists of a cluster B which includes multiple brokers b. Each broker is a process running on an operating system such as Linux. A broker abstracts a set of queues (partitions) associated with a topic.
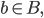
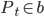
The leader and follower replicas for a partition is known as a replica set. Multiple replica sets logically become a topic when grouped into an ordered list. For the purposes of this paper, each replica consists of a leader replica and zero or more follower replicas. In practice, the partition may not have a leader elected and replicas may not be in-sync. However, for the purposes of this paper, we’ll be ignoring most ephemeral failure modes.
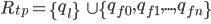
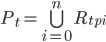
The capacity of each broker is defined by the packing of item  over bin
over bin 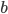 (we assume a bin packing approach by intuition). Initial placement of each replica on the brokers in the cluster can be modeled as random. Once a replica has been placed, properties of the replica, such as disk capacity, will change over time as messages are encountered. In addition, failure modes will skew the distribution of replica placement across all brokers in the cluster. Our goal is to minimize the use of resources at a single point in time.
(we assume a bin packing approach by intuition). Initial placement of each replica on the brokers in the cluster can be modeled as random. Once a replica has been placed, properties of the replica, such as disk capacity, will change over time as messages are encountered. In addition, failure modes will skew the distribution of replica placement across all brokers in the cluster. Our goal is to minimize the use of resources at a single point in time.
Basic Model
We relate the basic model[1] for bin packing to partitions in a cluster. Let 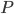 be the set of partitions. Each partition is associated with the capacity
be the set of partitions. Each partition is associated with the capacity 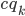 and each broker is associated with the capacity
and each broker is associated with the capacity 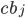 . For each queue
. For each queue 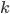 and each broker
and each broker 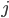 , a 0-1 membership variable
, a 0-1 membership variable 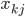 is defined. If variable is
is defined. If variable is  , is placed on broker , otherwise the variable is set to
, is placed on broker , otherwise the variable is set to 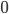 . To show the finite nature of a broker,
. To show the finite nature of a broker, 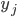 is introduced as a 0-1 variable. If is at capacity, the variable is set to , otherwise, it is set to
.
is introduced as a 0-1 variable. If is at capacity, the variable is set to , otherwise, it is set to
.
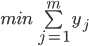
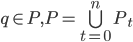
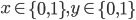
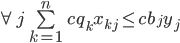
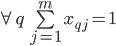
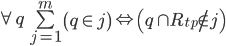
These initial constraints will the the foundation we’ll use to develop practical objectives. The first constraint ensures that the broker capacity is not exceeded. The second constraint ensures that each partition replica actually placed. Finally, the third constraint ensures that a replica is not collocated on a broker with other members of its in-sync set. In a future work, this may be extended to rack and cage capacity.
To reduce quadratic complexity, it is important to note that capacities may be interchanged (depending on similar attributes) to allow for membership symmetry.
Objectives
Although the cardinality of broker replica members has been used in the past as a constraint, this may be harmful on occasion as it does not reflect a response to an actual capacity limitation. For example, in practice, a high number of replicas may cause issues with file descriptor depletion, but this can be generally mitigated through tuning operating system parameters.
When balancing a cluster, three interrelated criteria should be used instead: replica disk capacity, per-broker network capacity, and topic retention policy. We assume that topics have reached a reasonable steady-state and retention policy is actively reached and applied. As all replicas should eventually approach steady-state, repeatedly applying a solution to the objective is still effective.
Topic retention policy and disk capacity are intertwined. Consider the case of a replica with time-based retention with an interval of 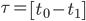 and disk capacity
and disk capacity 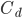 . We can then determine the throughput of the replica with
. We can then determine the throughput of the replica with  . Comparing this with the per-broker network capacity
. Comparing this with the per-broker network capacity 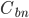 then allows us to build on the basic model to create a common capacity limitation constraint.
then allows us to build on the basic model to create a common capacity limitation constraint.
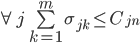
Conclusion
In this post we have presented a model as well as a set of four simple constraints that can be used to generate solutions to the replica balance problem using traditional linear programming techniques. We have determined that some existing methods, such as broker replica cardinality, are likely ineffective in achieving these goals. In the future, we may extend this model with a partition-replica consumption constraint.
[1] Régin, Jean-Charles, and Mohamed Rezgui. "Discussion about Constraint Programming Bin Packing Models." AI for data center management and cloud computing 24 Aug. 2011.