I've recently done some work on a very rough prototype of a Mesos scheduler for Samza. While going through the paces to get this working, I've noticed a few similarities between Mesos and Yarn that might be worth talking about.
The high-level architecture of both Yarn and Mesos are basically the same. Both resource managers have a master-slave architecture (both support a leader election via Zookeeper). In addition, both have adopted an SPMD MPI rank-0 style job control (the Scheduler and AppMaster) with job steps (tasks) managed by the rank-0. Here's a little diagram I've whipped up to compare similar functionality between the two.
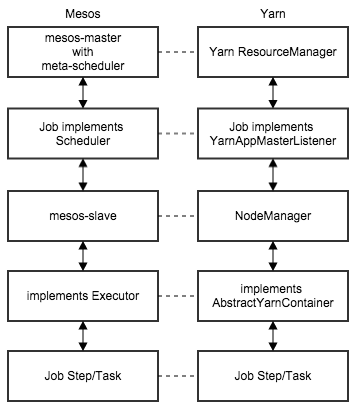
Starting from the top to the bottom, we first have the ResourceManager and mesos-master. This is where the state of the cluster is abstracted -- both have the ability to operate with the cluster state in Zookeeper, a replicated CP key-value store.
Below this, we have the rank-0 job abstraction, which is known as a Scheduler in Mesos land, and an Application Master when working with Yarn. Of note is that Yarn has the ability to restart a failed Application Master from the ResourceManager. However, Mesos seems to depend on a separate meta-scheduler (such as Marathon or Aurora) to restart a job.
Finally, at the bottom of the stack, the NodeManager and mesos-slave are compute node daemons that start the job step management. With Mesos, the job step management is known as the executor. With Yarn, it's known as the container. Both of these job step managers handle the fork/exec of the actual job step (task).
Although the architecture of Yarn and Mesos are very similar, there's a key difference in the way resources are allocated.
The Application Master and Scheduler have different models to gather resources from the master/manager. Most traditional resource managers, such as Slurm and Torque, follow the same design as Yarn. However, Mesos takes a different approach which was originally inspired by Google's Borg (see the Omega paper for details). You can think of the difference by considering how the resources are allocated by a job.
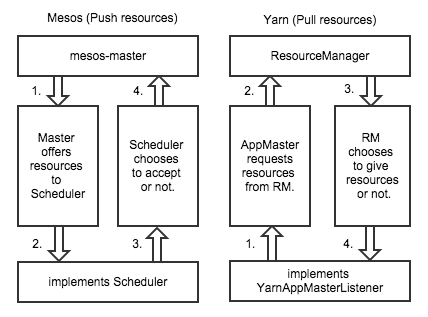
As you can see in the diagram above, Mesos follows a push model, while Yarn follows a pull model. From what I can see, a pull model is better for job submission throughput, while a push model is better for scalability across tens of thousands of servers.
So, when considering if you should use Mesos or Yarn, you should ask yourself if you have several large datacenters with long running services. If so, you should consider Mesos. If you have a ton of small batch jobs (like map-reduce jobs), Yarn may be a better choice.